
Tác giả: Alexander K. Hartmann
Đại học Gottingen, Đức
hartmann@theorie.physik.uni-goettingen.de
Heiko Rieger
Đại học Saarbrucken, Germany
rieger@lusi.uni-sb.de
1/2/2008
Tóm lược nội dung của bài báo “…”, vốn được trích từ cuốn sách: A.K. Hartmann and H. Rieger, Optimization Algorithms in Physics, (Wiley-VCH, Berlin, Weinheim 2001), ISBN 3-527-40307-8, với sự đồng ý của Wiley-VCH, xem http://www.wiley.com.
Bài báo gốc (bản tiếng Anh) có thể được tự do phân phối dưới dạng bản điện tử (file PDF) và bản in, nhưng không được thay đổi. Chính vì vậy trong bài post này, tôi chỉ tóm tắt lại nội dung bằng tiếng Việt sau đó chỉ đến những trang cụ thể để bạn đọc xem trong file tiếng Anh.
Tóm tắt
Bài này thảo luận các khía cạnh thực tế của việc tiến hành nghiên cứu bằng mô phỏng máy tính. Các vấn đề sau được làm rõ: gia công phần mềm, phát triển phần mềm hướng đối tượng, phong cách lập trình, macro, các file make, các văn lệnh, thư viện, số ngẫu nhiên, kiểm tra, gỡ lỗi, vẽ đồ thị, khớp đường cong, giãn tỉ lệ cỡ hữu hạn, truy cập thông tin, và chuẩn bị thuyết trình.
Do khuôn khổ có hạn, mỗi lĩnh vực thường chỉ có mục giới thiệu ngắn và có trích dẫn đến những học liệu bao quát vấn đề rộng hơn. Tất cả mã lệnh đều dùng ngôn ngữ C/C++.
Nội dung
1 Kĩ thuật phần mềm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Phát triển phần mềm hướng đối tượng. . . . . . . . . . . . . . 10
3 Phong cách lập trình . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4 Công cụ để lập trình . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1 Dùng macro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.2 Các file make . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.3 Các văn lệnh . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5 Những thư viện phần mềm . . . . . . . . . . . . . . . . . . . . . . . . 29
5.1 Phương pháp số . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.2 LEDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.3 Tự lập ra thư viện của riêng bạn . . . . . . . . . . . . . . . . . . 33
6 Số ngẫu nhiên . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6.1 Phát sinh số ngẫu nhiên . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.2 Phương pháp nghịch đảo . . . . . . . . . . . . . . . . . . . . . . . . 38
6.3 Phương pháp loại bỏ . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.4 Phân bố Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .41
7 Các công cụ kiểm thử chương trình . . . . . . . . . . . . . . . . . 42
7.1 gdb . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
7.2 ddd . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
7.3 checkergcc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
8 Đánh giá dữ liệu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
8.1 Vẽ đồ thị số liệu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
8.2 Khớp đường cong . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
8.3 Giãn tỉ lệ cỡ hữu hạn . . . . . . . . . . . . . . . . . . . . . . . . . . 55
9 Truy tìm thông tin và xuất bản . . . . . . . . . . . . . . . . . . . . 57
9.1 Tìm văn liệu nghiên cứu . . . . . . . . . . . . . . . . . . . . . . . . 58
9.2 Chuẩn bị xuất bản . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Trong tài liệu này, các khía cạnh thực dụng trong việc tiến hành nghiên cứu bằng mô phỏng máy tính đã được thảo luận. Giả thiết rằng bạn đã làm quen với một hệ điều hành kiểu UNIX (như Linux), một ngôn ngữ lập trình bậc cao như C, Fortran hoặc Pascal và có một chút kinh nghiệm với ít nhất là những dự án phần mềm nhỏ.
Do khuôn khổ có hạn, thường chỉ có những đoạn giới thiệu ngắn về các lĩnh vực cụ thể được trình bày, cùng những trích dẫn đến nguồn tài liệu phong phú. Tất cả ví dụ mã lệnh đều được viết bằng C/C++.
Trước hết là phần trình bày ngắn về kĩ thuật phần mềm và một số gợi ý cho phép lập trình mã lệnh hiệu quả và đáng tin cậy. Ở mục thứ hai có trình bày giới thiệu ngắn gọn về phát triển phần mềm hướng đối tượng. Cụ thể, bài viết còn cho thấy rằng phong cách lập trình này cũng có thể đạt được bằng những ngôn ngữ thủ tục tiêu chuẩn như C. Tiếp theo là những gợi ý thực dụng về quá trình thực sự viết mã lệnh. Ở mục thứ tư, các macro được giới thiệu. Sau đó trình bày cách phát triển những đoạn mã lệnh lớn hơn có thể được tổ chức nhờ các file make. Trong mục tiếp theo, lợi ích của việc dùng các thư viện như Numerical Recipes (Phương pháp số) hoặc LEDA được giải thích và cho bạn thấy cách tự thiết lập các thư viện riêng của bạn.
Trong mục thứ sáu, cách phát sinh số ngẫu nhiên sẽ được trình bày còn mục thứ 8 đề cập đến ba công cụ gỡ lỗi rất hữu ích. Sau đó, sẽ giải thích các chương trình thực hiện phân tích dữ liệu, khớp đường cong và giãn cỡ hữu hạn. Mục cuối là một đoạn giới thiệu về truy tìm thông tin, tìm kiếm tài liệu nghiên cứu trên mạng và cách chuẩn bị thuyết trình và xuất bản.
1. Kĩ thuật phần mềm
Hãy lập kế hoạch trước khi lao vào viết chương trình. Ngay cả khi bạn viết các chương trình nghiên cứu mà không hợp tác với ai. Lập kế hoạch giúp chương trình được linh động và dễ tìm lỗi. Lĩnh vực này có tên “Software engineering”, và được đề cập trong nhiều cuốn sách tin học. Những phương pháp trong kĩ thuật phần mềm gồm có:
- Định nghĩa vấn đề và chiến lược giải quyết
- Cần nhập vào dữ liệu gì? nhập ít dữ liệu qua dòng lệnh, hay có file thông số riêng?
- Cần thu nhận kết quả nào, cần phân tích những đại lượng gì? Số liệu thô (đầy đủ) hay số liệu nén (tiết kiệm dung lượng đĩa)?
- Bạn có thể nhận diện những “đối tượng” trong bài toán không? Đối tượng có thể là những thực thể (nguyên tử, phân tử) hay khái niệm tin học (nút, phần tử). Khi khái quát hóa hệ thống thành một cấu trúc phân cấp sẽ dễ thiết kế chương trình hơn.
- Chương trình về sau này có được mở rộng không? (khả năng tái sử dụng)
- Bạn có những chương trình nào có sẵn để có thể kèm vào trong dự án phần mềm không?
- Những thuật toán nào đã biết rồi? Hãy tìm những gì có sẵn trước khi sáng tạo, bởi sáng tạo mất nhiều thời gian.
- Thiết kế cấu trúc dữ liệu
Một khi đã nhận diện được các đối tượng cơ bản trong hệ thống, bạn cần nghĩ cách biểu diễn chúng. Thiết kế tỉ mỉ cấu trúc dữ liệu sẽ làm cho chương trình được tổ chức tốt hơn và thường chạy nhanh hơn.
Khi dùng các thư viện bên ngoài, các thư viện này thường có sẵn một số kiểu dữ liệu mà bạn có thể tận đụng để thiết kế chương trình.
- Định nghĩa những tác vụ nhỏ
Sau khi thiết lập các kiểu dữ liệu, bạn cần nghĩ về những thao tác đơn giản và phức tạp (thủ tục/chương trình con) để thao tác trên những đối tượng. Hãy chia nhiệm vụ lớn “mô phỏng” thành những tác vụ nhỏ (cách tiếp cận từ trên xuống / top down). Song khi viết lệnh thì phải thực hiện từ dưới lên. Nghĩa là bắt đầu viết từ những phép toán cơ bản nhất. Sau đó dùng những phép toán cơ bản này để lập những phép tính phức tạp hơn.
- Phân phối công việc
Trong trường hợp nhiều người đang cùng tham gia vào một dự án, thì bước tiếp theo là phân chia công việc giữa những cộng sự này. Nếu có vài kiểu đối tượng xuất hiện trong thiết kế chương trình, thì một cách tiếp cận tự nhiên sẽ là phân công từn người có trách nhiệm với một số đối tượng cùng những phép toán liên quan đến nó. Mã lệnh phải được chia thành nhiều mô đun (file mã nguồn), để cho mỗi mô đun chỉ do một người viết.
Khi nhiều người cùng biên tập một file mã lệnh, ta nên dùng hệ thống quản lý mã lệnh như RCS trong hệ GNU/Linux [5] (lưu ý cái này khá cổ điển).
- Viết mã lệnh
- Kiểm tra (testing)
- Các trường hợp kiểm tra (test case) cần đặc biệt và hiếm để phát hiện được lỗi.
- Thay vì cách thủ công (chèn lệnh print vào trong mã lệnh), hãy dùng bộ gỡ lỗi (debugger).
- Kiểm tra kết quả của bài toán nhỏ, so sánh nó với kết quả mà bạn tự nhẩm tính được.
- So sánh kết quả của nhiều phương pháp khác nhau với cùng một bài toán.
- Mỗi khi viết xong một chương trình con, hãy kiểm tra ngay nó.
- Giữ phiên bản mã lệnh cũ trước khi thay đổi, cải tiến.
- Lập trình C nên dùng tùy chọn bật tất cả cảnh báo (-Wall). Lưu ý dấu == thay vì =
- Viết tài liệu (documentation)
- Ghi chú (comment) trong mã nguồn
- Trợ giúp trực tuyến – theo nghĩa thông tin trợ giúp khi người dùng gọi chương trình từ cửa sổ lệnh
- Tài liệu ngoài
- Sử dụng mã lệnh: có một số vấn đề cần cân nhắc
- Mỗi lần chạy mất bao lâu? Trước hết nên chạy với các bài toán nhỏ, rồi suy ra thời gian chạy bài toán lớn
- Thời gian chạy nên được trung bình hóa với các mẫu khác nhau
- Kết quả lưu vào đâu? Cần tổ chức file và thư mục hợp lý, có file README để chỉ dẫn
- Các file log rất có ích để tự động ghi thông tin trong quá trình mô phỏng.
Các vấn đề trên không nhất thiết phải làm tuần tự. Phát triển phần mềm thường là một chu trình khép kín. Sau khi chạy chương trình, có thể quay về cải thiện khâu thiết kế.
2. Phát triển phần mềm hướng đối tượng
Phong cách lập trình hướng đối tượng khác với ngôn ngữ lập trình hướng đối tượng. Bạn có thể lập dự án với các phương thức hướng đối tượng mà chỉ cần những ngôn ngữ lập trình thủ tục như C, Pascal hay Fortran. Một số nguyên tắc khi phát triển phần mềm hướng đối tượng như sau:
- Đối tượng và phương thức. Các đối tượng được phân vào các lớp. Đối tượng có thể sở hữu trạng thái. Đối tượng hiện diện trong môi trường thể hiện bởi những hoạt động (phương thức tác động lên đối tượng đó). Đối tượng và các phương thức liên quan sẽ hình thành nên những khối rõ rệt. Từ quan điểm lập trình hướng đối tượng, chương trình có thể được tổ chức như một tập hợp các đối tượng gọi những phương thức của lẫn nhau.
- Bao gói dữ liệu. Nguyên tắc chung của lập trình hướng đối tượng là che giấu phần mã lệnh cấu thành những đối tượng. Việc truy cập đến đối tượng là được thực hiện thông qua giao diện, tức là các phương thức. Cấu trúc dữ liệu bên trong được ẩn giấu (từ khóa private trong C++). Việc bao gói dữ liệu có một số ưu điểm:
- Bạn không cần phải nhớ chi tiết cấu thành nên đối tượng; coi đối tượng như những hộp đen.
- Sau này bạn có thể thay đổi chi tiết cấu thành đối tượng mà không phải thay đổi toàn bộ chương trình. Rất cần nếu cần nâng cao hiệu năng chương trình hay bổ sung những tính năng mới.
- Bạn có cấu trúc dữ liệu linh hoạt, ví dụ cùng cấu trúc cây dữ liệu: nếu cây thưa thớt bạn có thể dùng kiểu con trỏ, cây dữ liệu đặc có thể dùng kiểu mảng.
- Dễ gỡ lỗi hơn.
- Thừa kế. Các đối tượng cấp thấp có thể là những dạng đặc biệt của đối tượng cấp cao hơn. Chẳng hạn trong vật lý có lớp “nguyên tử” và cấp thấp hơn là “nguyên tử tích điện” (thêm thuộc tính điện tích), và những đối tượng của lớp mới này vẫn dùng lại được các thủ tục tính toán như đối tượng lớp trên. Ngược lại, đối tượng cấp cao cũng có thể định nghĩa là tập hợp của các đối tượng cấp thấp.
- Trùng tải toán tử (operator overloading). Bạn có thể có những phương thức cùng tên để dùng với các lớp khác nhau. Ví dụ nếu dùng C hay Pascal thì các phép cộng số nguyên và cộng số phức phải được đặt tên khác nhau, còn trong C++ chỉ cần đặt một tên (toán tử “+”).
- Sử dụng lại phần mềm.
Như đã nói, ta vẫn có thể lập trình hướng đối tượng bằng các ngôn ngữ thủ tục như C. Chẳng ahjn, ta lập một lớp có tên “histo” để lập trình cho histogram bằng C.
#define _HISTO_NOM_ 9 /* No. of (statistical) moments */
/* holds statistical informations for a set of numbers: */
/* histogram, # of Numbers, sum of numbers, squares, ... */
typedef struct
{
double from, to; /* range of histogram */
double delta; /* width of bins */
int n_bask; /* number of bins */
double *table; /* bins */
int low, high; /* No. of data out of range */
double sum[_HISTO_NOM_]; /* sum of 1s, numbers, numbers^2 ...*/
} histo_t;
Ở đây histo_t là một kiểu dữ liệu. Ta có thể viết phương thức tạo lập và xóa bỏ histogram:
/** creates a histo-element, where the empirical histogram **/
/** table covers the range ['from', 'to'] and is divided **/
/** into 'n_bask' bins. **/
/** RETURNS: pointer to his-Element, exit if no memory. **/
histo_t *histo_new(double from, double to, int n_bask)
{
histo_t *his;
int t;
his = (histo_t *) malloc(sizeof(histo_t));
if(his == NULL)
{
fprintf(stderr, "out of memory in histo_new");
exit(1)
}
if(to < from)
{
double tmp;
tmp = to; to = from; from = tmp;
fprintf(stderr, "WARNING: exchanging from, to in histo_new\n");
}
his->from = from;
his->to = to;
if( n_bask <= 0)
{
n_bask = 10;
fprintf(stderr, "WARNING: setting n_bask=10 in histo_new()\n");
}
his->delta = (to-from)/(double) n_bask;
his->n_bask = n_bask;
his->low = 0;
his->high = 0;
for(t=0; t< _HISTO_NOM_ ; t++) /* initialize summarized moments */
his->sum[t] = 0.0;
his->table = (double *) malloc(n_bask*sizeof(double));
if(his->table == NULL)
{
fprintf(stderr, "out of memory in histo_new");
exit(1);
}
else
for(t=0; t<n_bask; t++)
his->table[t] = 0;
}
return(his);
}
/** Deletes a histogram 'his' **/
void histo_delete(histo_t *his)
{
free(his->table);
free(his);
}
Đối tượng histogram có thể được tạo bằng cách động thông qua việc gọi histo_new(), việc này tương ứng với gọi một constructor hay gọi new trong C++. Và khi không dùng đối tượng, ta gọi histo_delete(), tương ứng với destructor trong C++.
Ví dụ sau đây thực hiện việc chèn một phần tử vào bảng rồi tính trị trung bình. Toàn bộ mã lệnh có thể tham khảo ở [10].
/** inserts a 'number' into a histogram 'his'. **/
void histo_insert(histo_t *his, double number)
{
int t;
double value;
value = 1.0;
for(t=0; t< _HISTO_NOM_; t++)
{
his->sum[t]+= value;; /* raw statistics */
value *= number;
}
if(number < his->from)
/* insert into histogram */
his->low++;
else if(number > his->to)
his->high++;
else if(number == his->to)
his->table[his->n_bask-1]++;
else
his->table[(int) floor( (number - his->from) / his->delta)]++;
}
/** RETURNS: Mean of Elements in 'his' (0.0 if his=empty) **/
double histo_mean(histo_t *his)
{
if(his->sum[0] == 0)
return(0.0);
else
return(his->sum[1] / his->sum[0]);
}
3. Phong cách lập trình
Mã lệnh cần được viết theo phong cách thống nhất mà tác giả hoặc người khác sau này có thể hiểu và tiếp tục chỉnh sửa. Một số quy tắc như sau:
- Chia nhỏ mã lệnh thành nhiều module. Ưu điểm gồm có:
- Nếu cần sửa thì chỉ biên dịch lại những module nào thay đổi.
- Những thủ tục (hàm) nào liên quan với nhau thì có thể được gom về chung một module.
- Mỗi module một khi đã được hoàn thành và kiểm thử thì sẽ sử dụng được cho dự án khác.
- Có nhiều file (module) giúp các lập trình viên hợp tác tốt hơn so với 1 file (phải dùng Hệ thống quản lý phiên bản, CVS).
- Để giữ cấu trúc logic của chương trình, bạn cần đặt riêng từng file chứa cấu trúc dữ liệu và file thực hiện tính toán (như file .h và .c/.cpp).
- Gắng tìm những tên có ý nghĩa đặt cho các biến và hàm/thủ tục.
- Thụt đầu dòng thật chuẩn, giúp người đọc hiểu được cấu trúc chương trình.
- Tránh dùng những lệnh kiểu GOTO để nhảy đến chỗ khác trong chương trình.
- Không dùng biến toàn cục. Vẻ ngoài tiện dụng của biến toàn cục sẽ gây khó khăn sau này nếu có lỗi gây ra bởi việc dùng sai biến toàn cục: bạn phải kiểm tra một danh sách dài dằng dặc các biến.
- Đừng quá tiết kiệm lời chú thích mã lệnh. Các loại chú thích bao gồm:
- Chú thích module: ngay đầu mỗi module cần nêu rõ tên, công dụng, tác giả, thời điểm viết.
- Chú thích kiểu: với mỗi kiểu dữ liệu (struct trong C hay class trong C++) định nghĩa trong file header, bạn cần giải thích vài dòng về cấu trúc và ứng dụng của kiểu dữ liệu đó. Với lớp (class) thì giải thích cả những phương thức. Đồng thời mỗi phần tử trong cấu trúc cũng cần được giải thích.
- Chú thích hàm/thủ tục: giải thích công dụng của hàm/thủ tục này, những biến vào – ra và các điều kiện tiên quyết cần đảm bảo trước khi gọi. Nếu bạn dùng một phương pháp số hay thuật toán khéo léo để giải quyết vấn đề, nhất thiết phải ghi tên phương pháp hoặc thuật toán đó.
- Chú thích khối: một hàm có thể chia thành các khối theo logic, mỗi khối không nên dài quá 1 trang màn hình.
- Chú thích dòng lệnh
4. Công cụ lập trình
Macro
Macro là cách làm tắt để phát sinh ra đoạn mã lệnh. Trong C, macro được tạo thành bằng dẫn hướng #define, và được thực hiện trong giai đoạn tiền xử lý của trình biên dịch.
#define PI 3.1415926536
Sau đó, trong mã lệnh nếu có đoạn 2.0*PI*omega
thì bộ tiền xử lý sẽ chuyển đổi mã lệnh thành: 2.0*3.1415926536*omegaSong tất nhiên macro không được thay thế trong chuỗi kí tự như: printf(“PI”);
Có thể kiểm tra sự tồn tại của macro bằng dẫn hướng #ifdef , chẳng hạn
#ifdef UNIX
...
#endif
Một ví dụ là quản lý các file header trong dự án phần mềm lớn. Làm thế nào đảm bảo rằng một file header chỉ được đọc 1 lần mà không bị đọc lặp lại?
/** example .h file: myfile.h **/ #ifndef _MYFILE_H_ #define _MYFILE_H_ .... (rest of .h file) (may contain other #include directives) #endif /* _MYFILE_H_ */
Macro không chỉ đóng vai trò hằng số mà có thể nhận những đối số (tương tự một hàm):
#define MIN(x,y) ( (x)<(y) ? (x):(y) )
Lưu ý trong phần “định nghĩa” của “hàm” (macro) MIN, dấu ngoặc (x) và (y) là cần thiết. Song lưu ý rằng macro không giống như hàm. Chẳng hạn khi viết MIN(a++, b++) thì các biến a và b sẽ được tăng hai lần khi thực hiện chương trình.
Một ví dụ với macro là bài toán hệ thống Ising spin: một ma trận trong đó từng vị trí i có một hạt σi. Mỗi hạt có đúng hai trạng thái σi = ±1. Đánh số thứ tự các vị trí i = 1 đến N, trong một bảng vuông có cạnh L (N = L × L). Số được đánh từ góc trên bên trái, đánh hết hàng trên xuống hàng dưới.
Nếu vị trí thứ i không phải trên cạnh biên thì phần tử này sẽ tương tác với bốn spin: i + 1 (hướng +x), i – 1 (hướng -x), i + L (hướng +y), và i – L (hướng -i). Nếu phần tử ở đường biên, thì việc dùng dạng biên tuần hoàn sẽ đảm bảo cho phần tử đó vẫn có 4 tương tác với 4 vị trí xung quanh (xem hình). Xét lưới 10 x 10 thì spin thứ 5 (giữa hàng trên cùng) sẽ tương tác với các spin số 5 + 1 = 6 , 5 – 1 = 4 , 5 + 10 = 15, và số 95 (đối diện). Để xét đến trường hợp đối diện ta có thể tính modulo L (cho hướng ±x), và modulo L² (hướng ±y).

Để việc tính toán được thuận tiện, ta dùng ý tưởng thiết lập một ma trận liệt kê các vị trí lân cận (ma trận next); và có một chương trình con (không trình bày ở đây) để khởi tạo ma trận next này.
next là ma trận 1 chiều. Mỗi phần tử ở vị trí i có num_n phần tử lân cận (num_n = 4 với trường hợp trước); và vị trí của các lân cận này được lưu ở next[i*num_n], next[i*num_n+1], …, next[i*num_n + num_n -1]. Có thể dùng macro để truy cập i một cách tiện dụng như sau:
#define NEXT(i,r) next[(i)*num_n + r]
NEXT(i,r) chứa lân cận của phần tử i theo hướng r. Chẳng hạn, với lưới chữ nhật trong tọa độ Đề-các 2 chiều, r = 0 theo hướng +x, r=1 theo hướng -x, r=2 theo hướng +y, r=3 theo hướng -y (tùy bạn chọn thứ tự) và num_n = 4.
Trong hệ thống Ising, cần phải lưu lực tương tác (cả dấu lẫn độ lớn) giữa các phần tử vào một mảng j[]. Để truy cập vào mảng này được thuận tiện, ta lập macro J:
#define J(i,r) j[(i)*num_n + r]
Một chương trình con để tính năng lượng H = 
double spinglass_energy(int N, int num_n, int *next, int *j, short int *sigma)
{
double energy = 0.0;
int i, r; /* counters */
for(i=1; i<=N; i++) /* loop over all lattice sites */
for(r=0; r<num_n; r++) /* loop over all neighbors */
energy += J(i,r)*sigma[i]*sigma[NEXT(i,r)];
return(energy/2); /* each pair has appeared twice in the sum */
}
trong đó N là số các spin (phần tử).
File make
Khi dự án phần mềm phình to ra, nó sẽ gồm vài file mã nguồn khác nhau. Thường sẽ nảy sinh sự ràng buộc giữa các file, chẳng hạn một kiểu dữ liệu được định nghĩa trong file header này có thể được dùng trong vài module khác. Do vậy, khi thay đổi một trong các file mã nguồn, có thể ta sẽ phải biên dịch lại một phần của chương trình. Nếu không muốn phải biên dịch thủ công, bạn có thể chuyển nhiệm vụ này cho công cụ make trên nền UNIX/Linux. Xem thêm chi tiết về file make trong [12].
Ý tưởng cơ bản của file make là bạn giữ một file có chứa tất cả ràng buộc giữa các file mã nguồn (sources) với nhau. Hơn nữa, nó cũng bao gồm các lệnh (như lệnh biên dịch) để sinh ra các file kết quả (file đích, target) là những chương trình hoặc file đối tượng (.o) (object file). Mỗi cặp ràng buộc và câu lệnh hợp thành một quy tắc (rule). File có chứa tất cả những quy tắc này cho một dự án phần mềm được gọi là file make. Nó thường được đặt tên Makefile và nằm ở thư mục chứa các file mã nguồn.
Quy luật được viết dưới dạng
target : sources
<tab> commands
Trong đó dòng thứ nhất chứa các ràng buộc còn dòng theo sau là (các) lệnh. Các dòng sau phải bắt đầu bằng dấu <tab>. Được phép dùng file đích khác nhau cho cùng một nguồn. Bạn có thể kéo dài các dòng sau với dấu \ ở cuối mỗi dòng. Một dòng lệnh cũng được phép để trống. Một ví dụ về cặp ràng buộc/lệnh như sau:
simulation.o: simulation.c simulation.h <tab> cc -c simulation.c
Điều này có nghĩa rằng file simulation.o phải được biên dịch nếu file simulation.c hoặc simulation.h bị thay đổi. Chương trình make được gọi khi ta gõ make vào dòng lệnh UNIX. Máy sẽ xem ngày giờ thay đổi cuối cùng, vốn được lưu giữ theo file, để quyết định xem có cần lập lại các file đích không. Đặc biệt, khi không có file đích, thì lệnh sẽ được gọi.
Cũng có thể tạo nên các quy tắc meta, tức là chỉ dẫn cách xử lý tất cả những file có phần đuôi tên cụ thể nào đó.
Lưu ý rằng công cụ make chỉ cố gắng biên dịch nên file đối tượng đầu tiên được yêu cầu trong file make, nên để biên dịch ra nhiều file đối tượng object1, object2, object3, cần thêm một quy luật đầu tiên như sau:
all: object1 object2 object3 object1: <các file mã nguồn của object1> <tab> <câu lệnh để tạo ra object1> object2: ... <tab> <câu lệnh để tạo ra object2> object3: ... <tab> <câu lệnh để tạo ra object3>
Còn nếu bạn chỉ muốn biên dịch lại đối tượng 3, thì hãy gõ lệnh make object3.
Thường người ta sẽ viết đích clean trong file make để cho tất cả file đối tượng được xóa đi sau khi gọi make clean. Bằng cách đó, lần gọi sau chỉ gõ make sẽ biên dịch toàn bộ chương trình từ đầu. Quy tắc với clean sẽ như sau:
clean: <tab> rm -f *.o
Thứ tự của các quy tắc không quan trọng trừ quy tắc thứ nhất là cái mà công cụ make luôn thực hiện đầu tiên.
Bạn cũng có thể định nghĩa các biến, đôi khi còn được gọi là macro theo mẫu:
biến=định nghĩa
Các biến môi trường như $HOME cũng dùng được trong file make nhưng tên biến phải được bọc trong cặp ngoặc: $(HOME) hoặc ${HOME}. Biến CC được chỉ định là lệnh biên dịch, bạn có thể thay đổi nó bằng cách viết, chẳng hạn,
CC=gcc
trong file make. Trong phần lệnh của một một quy tắc, ta sẽ gọi với tên $(CC).
Một ví dụ mô phỏng: chương trình khi hoàn thành sẽ có tên simulation. Có hai module init.c, run.c và các file .h tương ứng. Trong file datatypes.h, các kiểu dữ liệu được định nghĩa để dùng trong module. Ngoài ra, một file đối tượng đã biên dịch sẵn, analysis.o trong thư mục $HOME/lib cần được liên kết đến, và coi như file header tương ứng được đặt trong $HOME/include. Với init.o và run.o không cần câu lệnh nào. TRong trường hợp này, make áp dụng các lệnh tiêu chuẩn định nghĩa sẵn với những file có phần đuôi tên là .o, cụ thể:
<tab> $(CC) $(CFLAGS) -c $@
trong đó biến CFLAGS có thể chứa những tùy chọn được truyền đến trình biên dịch và ban đầu thì biến này để trống. Toàn bộ file make như sau, lưu ý rằng các dòng bắt đầu bằng dấu # là dòng chú thích:
# # sample make file # OBJECTS=simulation.o init.o run.o OBJECTSEXT=$(HOME)/lib/analysis.o CC=gcc CFLAGS=-g -Wall -I$(HOME)/include LIBS=-lm
simulation: $(OBJECTS) $(OBJECTSEXT) <tab> $(CC) $(CFLAGS) -o $@ $(OBJECTS) $(OBJECTSEXT) $(LIBS)
$(OBJECTS): datatypes.h
clean: <tab> rm -f *.o
Văn lệnh (script)
Văn lệnh là những công cụ thậm chí còn tổng quát hơn file make. Thực ra, đó là các chương trình nhỏ, song không được biên dịch: văn lệnh là những chương trình ngắn được soạn ra nhanh chóng nhưng chạy tương đối chậm. Văn lệnh có thể được dùng để thực hiện công việc quản lý hệ thống như sao lưu dữ liệu, cài đặt phần mềm hoặc chạy nhiều chương trình mô phỏng với nhiều thông số. Văn lệnh có thể được viết bằng Bourne Shell (bash) trong Linux, hoặc Perl hay Python, v.v.
5. Thư viện
Thư viện là tập hợp các chương trình con và kiểu dữ liệu mà ta có thể dùng trong các chương trình khác. Có những thư viện về phương pháp số như tính tích phân hay giải phương trình vi phân, thư viện để tìm kiếm và sắp xếp dữ liệu, thư viện dành cho các kiểu dữ liệu đặc biệt như danh sách hoặc cây, hay thư viện đồ họa … Việc sử dụng thư viện sẽ rút ngắn thời gian phát triển phần mềm đáng kể. Bởi vậy luôn cần phải kiểm tra xem có sẵn thư viện hỗ trợ không, trước khi bạn bắt tay viết chương trình. Ở đây, chúng tôi trình bày hai thư viện phục vụ mô phỏng. Và mục cuối sẽ đề cập đến cách tự tạo thư viện của riêng bạn.
Numerical Recipes
Numerical Recipes hay NR [3] là thư viện chứa nhiều chương trình con để giải các bài toán số trị như:
- giải phương trình tuyến tính
- nội suy
- lượng giá hàm và tính tích phân
- giải phương trình phi tuyến
- cực tiểu hóa các hàm
- chéo hóa ma trận
- biến đổi Fourier
- giải các phương trình vi phân thường và vi phân riêng
Chẳng hạn, đoạn chương trình sau để tính các giá trị riêng:
#include <stdio.h>
#include <stdlib.h>
#include "nrutil.h"
#include "nr.h"
int main(int argc, char *argv[])
{
float **m, *d, *e; /* 1 ma tran, 2 vecto */
long n = 10; /* kich thuoc cua ma tran */
int i, j; /* loop counter */
m = matrix(1, n, 1, n); /* cap phat bo nho cho ma tran */
for(i=1; i<=n; i++) /* khoi tao ma tran mot cach ngau nhien */
for(j=i; j<=n; j++)
{
m[i][j] = drand48();
m[j][i] = m[i][j]; /* o day, ma tran phai doi xung */
}
d = vector(1,n); /* cac phan tu tren duong cheo chinh */
e = vector(1,n); /* cac phan tu ngoai duong cheo chinh */
tred2(m, n, d, e); /* chuyen ma tran doi xung m. -> ba duong cheo */
tqli(d, e, n, m); /* tinh cac gia tri rieng */
for(j=1; j<=n; j++) /* in nhung gia tri hien luu trong mang 'd' */
printf("ev %d = %f\n", j, d[j]);
free_vector(e, 1, n); /* tra lai bo nho */
free_vector(d, 1, n);
free_matrix(m, 1, n, 1, n);
return(0);
}
LEDA
Nếu như Numerical Recipes được dành riêng cho các bài toán số trị, thì Library of Efficient Data types and Algorithms (LEDA, Thư viện thuật toán và kiểu dữ liệu hiệu quả) [4] có thể trợ giúp nhiều trong việc lập trình nói chung. Thư viện được viết bằng C++, nhưng từ C cũng có thể gọi đến các thủ tục C++ được. LEDA có chứa nhiều kiểu dữ liệu cơ bản và nâng cao như:
- chuỗi
- số với độ chuẩn xác tùy ý
- mảng 1 và 2 chiều
- danh sách và những đối tượng tương tự khác như ngăn xếp và hàng đợi
- tập hợp
- cây
- đồ thị (có hướng, không hướng, có gán nhãn)
- từ điển, ở đó bạn có thể lưu những đối tượng với các từ khóa tùy ý đóng vai trò chỉ số
- những kiểu dữ liệu trong hình học 2 và 3 chiều như các điểm, đoạn thẳng hay hình cầu.
Một chương trình có dùng LEDA cần được biên dịch bằng trình biên dịch C++. Tùy theo hệ thống máy tính của bạn, có thể dùng những cờ phù hợp, chẳng hạn:
g++ -I$LEDAROOT/incl -L$LEDAROOT -o leda_test leda_test.cc -lG -lL
Viết riêng thư viện của bạn
Tập hợp các chương trình con bạn thường hay dùng có thể đưa vào thư viện: khi đó bạn không cần phải nạp (include) file object mỗi khi biên dịch chương trình của mình. Nếu thư viện tự tạo của bạn được đặt trong một đường dẫn tìm kiếm chuẩn, thì bạn có thể truy cập nó như một thư viện hệ thống, và thậm chí không cần nhớ xem file đối tượng đó nằm ở đâu.
Để tạo một thư viện bạn cần phải có một file đối tượng như task.o và một file header task.h trong đó mọi kiểu dữ liệu và nguyên mẫu của hàm được định nghĩa. Ngoài ra, để dễ sử dụng thư viện, bạn nên viết một trang hướng dẫn (man page) trong hệ thống UNIX. Từ dấu nhắc hệ thống, bạn dùng câu lệnh ar:
ar r libmy.a tasks.o
Một thư viện có thể tập hợp vài file object. Tùy chọn “r” thay thế các file object đã cho, nếu chúng sẵn thuộc về thư viện; nếu không chúng sẽ được bổ sung thêm. Nếu thư viện chưa tồn tại thì sẽ được tạo ra.
Sau khi bao gồm file object, ta cần phải cập nhật bảng đối tượng nội trong thư viện. Điều này được thực hiện nhờ lệnh:
ar s libmy.a
Bây giờ bạn có thể biên dịch một chương trình prog.c có dùng thư viện mới lập, bằng lệnh:
cc -o prog prog.c libmy.a
6. Số ngẫu nhiên
Việc phát sinh số ngẫu nhiên được dùng nhiều kể cả khi hệ thống không mang tính ngẫu nhiên. Mục này sẽ giới thiệu các phương pháp khác nhau: phương pháp đảo, phương pháp Box-Muller và phương pháp bác bỏ. Chi tiết về các phương pháp này và phương pháp khác có ở [3, 16].
6.1 Phát sinh số ngẫu nhiên
Máy tính thực hiện tính toán theo cách đã định sẵn, bởi vậy yếu tố ngẫu nhiên phải từ bên ngoài (ít ra là từ người dùng). Ví dụ khoảng thời gian giữa những lần gõ phím kế tiếp. Song ngẫu nhiên hoàn toàn thì lại không thể tái hiện lại được thí nghiệm. Bởi vậy người ta thường phát sinh số giả ngẫu nhiên. Việc phát sinh được thực hiện bằng nhữn quy tắc xác định, nhưng kết quả lại có dáng dấp giống những số ngẫu nhiên thực thụ.
Phần còn lại của mục này, bạn có thể xem lại Bài “Phát sinh các số giả ngẫu nhiên”.
7. Các công cụ kiểm thử
Những công cụ này hoạt động trong môi trường UNIX/Linux, gồm có: gdb (trình gỡ lỗi), ddd (giao diện đồ họa cho gdb), và checkergcc (tìm những lỗi gây ra do quản lý sai bộ nhớ).
7.1 gdb
gdb (GNU debugger) là trình gỡ lỗi. Khi dùng nó, bạn có thể theo dõi dòng thực thi mã lệnh. Bạn có thể dừng chương trình tại những điểm bất kì định trước bằng cách đặt các breakpoint tại các dòng hoặc các chương trình con. Với chương trình ngắn sau:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int t, *array, sum = 0;
array = (int *) malloc (100*sizeof(int));
for(t=0; t<100; t++)
array[t] = t;
for(t=0; t<100; t++)
sum += array[t];
printf("sum= %d\n", sum);
free(array);
return(0);
}
Khi biên dịch, nhớ chọn -g để có thể gỡ lỗi:
cc -o gdbtest -g gdbtest.c
Sau đó kích hoạt gỡ lỗi bằng lệnh:
gdb gdbtest
Một số lệnh để gõ vào dấu nhắc (gdb) có thể là
(gdb) 1
Liệt kê toàn văn file lệnh (từ dòng 1)
(gdb) b 11
Đặt breakpoint tại dòng 11
(gdb) r
Chạy chương trình
(gdb) p array (gdb) p array[99]
In ra mảng hoặc phần tử của mảng.
(gdb) set array (gdb) n
Đặt giá trị một phần tử của mảng. Sau đó chạy tiếp.
Mặt khác, có thể chạy chương trình theo từng bước
(gdb) step
và dò từng bước để tìm ra lỗi rồi thì bạn có thể tiếp tục chạy đến hết chương trình (hoặc đến breakpoint kế tiếp, nếu còn):
(gdb) continue
7.2 ddd
Đây là giao diện đồ họa của công cụ gỡ lỗi, xem hình.

7.3 checkergcc
Trong nhiều trường hợp chương trình đổ vỡ vì quản lý, truy cập bộ nhớ không hợp lệ. Thông báo lỗi có thể là Segmentation fault. Để phát hiện những lỗi đáng sợ này, ta có thể dùng một số công cụ [19]. Ở đây chúng tôi giới thiệu checkergcc, một công cụ tiện lợi và miễn phí. Nó chạy trong môi trường UNIX và biên dịch bằng checkergcc thay vì cc hay gcc. Thật không may là nó không hỗ trợ hoàn toàn cho C++, nhưng bạn cứ thử dùng xem. Trình biên dịch này sẽ thay thế tất cả việc cấp phát, giải phóng, truy cập bộ nhớ bằng những chương trình con riêng. Bất kì việc truy cập bộ nhớ trái phép nào cũng sẽ được báo cáo.
Với đoạn chương trình trên có thể biên dịch:
checkergcc -o gdbtest -g gdbtest.c
Sau đó kích hoạt gỡ lỗi:
gdbtest
8. Đánh giá dữ liệu
Dưới đây sẽ trình bày cách dùng gnuplot để xem và khớp dữ liệu trực tiếp trên máy, còn xmgr để tạo ra các hình vẽ trong các ẩn phẩm. fsscale là một chương trình tiện dụng để thu phóng kích thước hữu hạn (một phương pháp phân tích chuyên ngành vật lý tính toán).
8.1 Vẽ đồ thị
Chương trình gnuplot chạy trong môi trường UNIX cung cấp một cửa sổ dòng lệnh, ngoài ra còn thông dịch được các file văn lệnh (script). Chẳng hạn một file command.gp sẽ được thực hiện bằng câu lệnh:
gnuplot command.gp
Một ví dụ: ta vẽ đồ thị file sg_e0_L.dat. Cột đầu là các giá trị L, cột thứ hai là giá trị năng lượng và cột thứ ba sai số chuẩn của năng lượng. Lưu ý: các dòng bắt đầu bằng dấu # là dòng ghi chú.
# ground state energy of +-J spin glasses # L e_0 error 3 -1.6710 0.0037 4 -1.7341 0.0019 5 -1.7603 0.0008 6 -1.7726 0.0009 8 -1.7809 0.0008 10 -1.7823 0.0015 12 -1.7852 0.0004 14 -1.7866 0.0007
Để vẽ đồ thị số liệu này, gõ lệnh
gnuplot> plot "sg_e0_L.dat" with yerrorbars
Dòng lệnh này có thể viết gọn là
p "sg e0 L.dat" w e
với kết quả như hình dưới

Để in ra file eps thì trước đó cần gõ vào lệnh
set terminal postscript
set output "test.eps"
Có thể chỉnh sửa tiêu đề trục, chẳng hạn như
set xlabel "L"
Chương trình xmgr (viết tắt của x motiv graphic) có tính năng mạnh hơn nhưng chạy chậm hơn gnuplot một chút. Và phải dùng chuột click các menu và menu con. Có thể vẽ nhiều loại biểu đồ với đừng nét và kí hiệu khác nhau, có thể viết kí hiệu lên bản vẽ.


8.2 Khớp đường cong
Cả hai chương trình gnuplot và xmgr nêu trên đều khớp được đường cong cho nhiều dạng hàm khác nhau. Nên dùng gnuplot vì nó linh động hơn, và cũng cung cấp thông tin kĩ hơn để đánh giá chất lượng khớp.
Giả sử cần khớp hàm 
gnuplot> f(x)=e+a*x**b gnuplot> e=-1.8 gnuplot> a=1 gnuplot> b=-1
Việc khớp được thực hiện qua lệnh fit. Thuật toán được dùng là Marquardt-Levenberg [3], vốn cho ta
gnuplot> fit f(x) "sg_e0_L.dat" via e,a,b
Gnuplot sẽ in ra nhiều thông tin về kết quả khớp hàm này. Có kết quả về số bậc tự do, sai số (theo chỉ tiêu khi-bình phương).
Để xem kết quả khớp cùng với số liệu gốc, ta chỉ cần gõ lệnh:
gnuplot> plot "sg_e0_L.dat" w e, f(x)

Lưu ý rằng độ hội tụ phép khớp đường cong này phụ thuộc vào giá trị ban đầu của các tham số. Thuật toán có thể sa vào cực tiểu địa phương nếu các tham số nằm quá xa giá trị tối ưu của chúng. Hãy thử đặt các giá trị ban đầu e=1, a=-3 và b=1 !
Ngoài ra, không cần thiết phải thay đổi tất cả các tham số trong phép khớp: tham số nào giữ nguyên thì bỏ ra ngoài lệnh fit.
Có thể đặt trọng số cho các tham số; hãy thử lệnh
fit f(x) "sg e0 L.dat" using 1:2:3 via a,b,c
8.3 Thu phóng kích thước hữu hạn
Trong vật lý thống kê, ứng xử của các hệ thống được biểu diễn bằng rất nhiều hạt (phần tử). Số lượng các hạt này quá nhiều, không dễ biểu diễn trên máy tính. Do đó, người ta đưa vào kĩ thuật “thu phóng kích thước hữu hạn” (finite-size scaling), xem [21]. Ý tưởng cơ bản là mô phỏng các hệ thống với các kích thước khác nhau rồi ngoại suy ra giá trị giới hạn ứng với hệ thống lớn.
Sau đây là phần thực hằng bằng gnuplot và fsscale. Xét độ từ hóa m của thủy tinh spin 3 chiều với tỉ lệ p phần liên kết phi-sắt từ và 1 – p phần sắt từ. Với p nhỏ thì đúng như dự kiến: hệ thống có trạng thái trật tự sắt từ, xem hình biểu diễn trường hợp L = 3, 5,14.

Giờ cần tìm giá trị tới hạn của p là 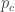

với 






gnuplot> b=0.27 gnuplot> n=1.1 gnuplot> pc=0.222 gnuplot> plot [-1:1] "m_scale.dat" u (($2-pc)*$1**(1/n)):($3*$1**(b/n))
Ở đây $1, $2, $3 là số liệu trên các cột 1, 2, 3 của file. Kết quả biểu đồ thu được, và ta quan sát được

Công việc được thuận tiện hơn khi dùng fsscale [22], link ftp://ftp.thp.uni-duisburg.de/pub/fsscale/ .

Trong file đầu vào fsscale có 3 cột: cột thứ nhất là kích thước hệ thống, cột 2 các giá trị của x, và cột 3 các giá trị của.
Nếu có nhiều cột quá, bạn có thể dùng awk trong UNIX để trích ra những cột cần thiết.
9. Truy tìm thông tin và xuất bản
9.1 Tìm tài liệu
Nhiều thông tin cần cho nghiên cứu lại không có trong sách giáo khoa thông thường. Sẽ rất tốt nếu bạn thạo dùng trình duyệt để truy cập Internet. Một số nguồn lưu trữ thông tin gồm có
- Trong thư viện
- Trong cơ sở dữ liệu toàn văn nghiên cứu
- Trên hệ thống máy chủ lưu file bản thảo
- Trong các tạp chí (tập san) khoa học
- Trong cơ sở dữ liệu trích dẫn
- Các trang đặc biệt (như Phys Net)
- Google, v.v.
9.2 Chuẩn bị xuất bản
Với bản thảo viết, bạn nên dùng TeX/LaTeX với các ưu điểm:
- Chất lượng bản thảo đẹp
- Quản lý được văn bản đồ sộ
- Dễ đánh công thức toán học
- Nhiều gói phần mềm để mở rộng tính năng và kiểu dáng văn bản
- Dùng trình soạn thảo văn bản đơn giản
- Vẫn có trình soạn thảo công phu với giao diện đồ họa như LyX [42].
Đoạn mã sau sẽ tạo ra văn bản thể loại “bài báo khoa học” với font cỡ 12 và hiển thị chữ nghiêng, chữ đậm, chữ nhỏ, logo LaTeX cùng phương trình toán học:
\documentclass[12pt]{article}
\begin{document}
This is just a small sample text. You can write some words {\em
emphasized}\/, or in {\bf bold face}. Also different {\small sizes}
are possible.
An empty line generates a new paragraph. \LaTeX\ is very convenient
for writing formulae, e.g.
\begin{equation}
M_i(t) = \frac{1}{L^3} \int_V x_i \rho(\vec{x},t) d^3\vec{x}
\end{equation}
\end{document}
Xem các hướng dẫn thêm về LaTeX [40,41].
Trong môi trường UNIX/Linux, trình kiểm tra chính tả tiếng Anh là ispell có thể dùng để soát văn bản LaTeX.
Nhiều văn bản báo cáo khoa học trình bày các sơ đồ hình vẽ. Một công cụ đơn giản, tiện dụng để tạo sơ đồ là xfig. Chương trình này cho phép tạo bản vẽ vec tơ (đường thẳng, mũi tên, đường cong, đa giác, cung tròn, chữ nhật, … và có thể thêm chữ viết, file hình ảnh (eps, jpg)). Các đối tượng hình có thể được đặt trên các lớp khác nhau. Có thể thao tác lên các đối tượng (dịch chuyển, xoay hình, phóng to – thu nhỏ, ghép hình, v.v.) Dưới đây là minh họa sử dụng xfig để vẽ một sơ đồ tính toán.

Để tạo ra các sơ đồ mô hình 3 chiều, có thể dùng công cụ PovRay (Persistence of Vision RAYtracer) [43]. PovRay là một chương trình raytracer (chương trình tạo nên hình ảnh bằng cách phát một số tia sáng từ nguồn và theo dõi quá trình truyền của nó (hấp thụ, phản xạ, khúc xạ khi truyền) đến khi tia sáng này lọt vào camera hay bị tắt hết. Quá trình tính truyền này có thể rất lâu tùy theo độ phức tạp của khung cảnh. Kết quả sẽ là một file ảnh giống như được chụp thật.
Một khung cảnh có thể được khai báo bởi file văn bản. Chẳng hạn, file khung cảnh sau có 3 khối cầu được nối bởi hai khối trụ, và một mặt phẳng ngang cùng màu sắc của vật thể được chỉ định.
#include "colors.inc"
background { color White }
sphere { <10, 2, 0>, 2
pigment { Blue } }
cylinder { <10, 2, 0>, <0, 2, 10>, 0.7
pigment { color Red } }
sphere { <0, 2, 10>, 4
pigment { Green transmit 0.4} }
cylinder { <0, 2, 10>, <-10, 2, 0>, 0.7
pigment { Red } }
sphere { <-10, 2, 0>, 2
pigment { Blue } }
plane { <0, 1, 0>, -5
pigment { checker color White, color Black}}
light_source { <10, 30, -3> color White}
camera {location <0, 8, -20>
look_at <0, 2, 10>
aperture 0.4}

Tài liệu tham khảo
[1] I. Sommerville, Software Engineering , (Addisin-Wesley, Reading (MA) 1989)
[2] C. Ghezzi, M. Jazayeri, and D. Mandrioli, Fundamentals of Software Engineering , (Prentice Hall, London 1991)
[3] W.H. Press, S.A. Teukolsky, W.T. Vetterling, and B.P. Flannery, Numerical Recipes in C (Cambridge University Press, Cambridge 1995)
[4] K. Mehlhorn and St. Naher, The LEDA Platform of Combinatorial and Geometric Computing (Cambridge University Press, Cambridge 1999); xem thêm http://www.mpi-sb.mpg.de/LEDA/leda.html
[5] M. Loukides and A. Oram, Programming with GNU Software , (O’Reilly, London 1996); xem thêm http://www.gnu.org/manual
[6] H.R. Lewis and C.H. Papadimitriou, Elements of the Theory of Computation, (Prentice Hall, London 1981)
[7] J. Rumbaugh, M. Blaha, W. Premerlani, F. Eddy, and W. Lorensen, Object-Oriented Modeling and Design, (Prentice Hall, London 1991)
[8] R. Johnsonbaugh and M. Kalin, Object Oriented Programming in C++, (Macmillan, London 1994)
[9] J. Skansholm, C++ from the Beginning , (Addisin-Wesley, Reading (MA) 1997)
[10] Gửi Mail đến hartmann@theorie.physik.uni-goettingen.de
[11] B.W. Kernighan and D.M. Ritchie, The C Programming Language, (Prentice Hall, London 1988)
[12] A. Oram and S. Talbott, Managing Projects With Make, (O’Reilly, London 1991)
[13] Các chương trình và hướng dẫn sử dụng có thể tìm thấy ở http://www.gnu.org. Một số có cả file texinfo. Để đọc file này, khởi động trình biên tập “emacs” rồi gõ <crtl>+h tiếp theo là i để vào chế độ texinfo.
[14] J. Phillips, The Nag Library: A Beginner’s Guide (Oxford University Press, Oxford 1987); xem thêm http://www.nag.com
[15] A. Heck, Introduction to Maple , (Springer-Verlag, New York 1996)
[16] B.J.T. Morgan, Elements of Simulation, (Cambridge University Press, Cambridge 1984)
[17] A.M. Ferrenberg, D.P. Landau and Y.J. Wong, Phys. Rev. Lett. 69, 3382 (1992); I. Vattulainen, T. Ala-Nissila and K. Kankaala, Phys. Rev. Lett. 73, 2513 (1994)
[18] J.F. Fernandez and C. Criado, Phys. Rev. E 60, 3361 (1999)
[19] http://www.cs.colorado.edu/homes/zorn/public html/MallocDebug.html
[20] Giấy phép công cộng gnu có thể lấy về từ http://www.gnu.org/software/checker/checker.html
[21] J. Cardy, Scaling and Renormalization in Statistical Physics, (Cambridge University Press, Cambridge 1996)
[22] Chương trình fsscale được viết bởi A. Hucht, có thể liên lạc tác giả thông qua email: fred@thp.Uni-Duisburg.DE
[23] A.K. Hartmann, Phys. Rev. B 59 , 3617 (1999)
[24] K. Binder and D.W. Heermann, Monte Carlo Simulations in Statistical Physics , (Springer, Heidelberg 1988)
[25] http://www.inspec.org/publish/inspec/
[26] http://xxx.lanl.gov/
[27] http://www.aip.org/o js/service.html
[28] http://publish.aps.org/
[29] http://www.elsevier.nl
[30] http://www.eps.org/publications.html
[31] http://www.iop.org/Journals/
[32] http://www.springer.de/
[33] http://www.wiley-vch.de/journals/index.html
[34] http://ejournals.wspc.com.sg/journals.html
[35] http://wos.isiglobalnet.com/
[36] http://physnet.uni-oldenburg.de/PhysNet/physnet.html
[37] http://www.yahoo.com/
[38] http://www.altavista.com/
[39] http://www.metacrawler.com/index.html
[40] L. Lamport and D. Bibby, LaTeX : A Documentation Preparation System User’s Guide and Reference Manual, (Addison Wesley, Reading (MA) 1994)
![\begin{array}{rcl} \frac{dr_i}{dt} &=& v_i,\\[0.5ex] \frac{dv_i}{dt} &=& - \frac{e\,E(r_i)}{m_e}, \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D++%5Cfrac%7Bdr_i%7D%7Bdt%7D+%26%3D%26+v_i%2C%5C%5C%5B0.5ex%5D++%5Cfrac%7Bdv_i%7D%7Bdt%7D+%26%3D%26+-+%5Cfrac%7Be%5C%2CE%28r_i%29%7D%7Bm_e%7D%2C++%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)



